JPEG Compression Algorithm and Associated Data Structures
Mark D. Schroeder
University of North Dakota
http://www.cs.und.edu/~mschroed/index.html
marschro@badlands.nodak.edu
Table of Contents
Abstract
JPEG, an image compression standard sanctioned by the ISO (International Standards Organization), gives users the ability to take an image and compress it with little or no noticeable quality degradation. The original image is taken through a series of steps, (initial input, Discrete Cosine Transform, quantizat ion, and enc oding) each of which contributes to the overall compression of the image. Compression ratios for a 24-bit color image can be as high as 100:1! At that ratio, however, there is noticeable image degradation, even at normal magnification. Usual image compression ranges from 10:1 to as high as 20:1 without any visible image degradation (Leemans, n.d.).
Introduction
High quality digitized images have always been subject to an unfortunate correlation: high image quality equals large file size. With the rapid progression of image input devices and the explosion of the Internet in the late 80’s and early 90’s, the demand for a high quality, highly compressive algorithm for image compression developed. GIF, a popular lossless image format whose compression algorithm is patented by Unisys, was introduced to the public by CompuServe. However, GIF i s only practical when using a maximum of 256 colors. With modern display hardware capable of displaying true 16 and 24-bit color, GIF is becoming obsolete.
A good answer to the image compression problem is the JPEG compression algorithm. I say algorithm intentionally, because the actual file format defined in the JPEG standard is the Still Picture Interchange File Format (SPIFF) (O'Reilly & Associates, Inc., 1996 , http://www.ipahome.com/gff/textonly/summary/spiff.htm). Although the JPEG algorithm is lossy, it can be very effectively applied to a 24-bit color image, achieving compression ratios of 10:1 to 20:1 without any image degradation that is visible to the human eye at normal magnification (King, May 1997).
Since its original inception, several additions have been made to the JPEG algorithm. The previously mentioned file format, SPIFF, is a new addition to the JPEG standard, which originally had no definition for a standard file format. The de facto file format for JPEG compressed images was JFIF. Fortunately, SPIFF is backwards compatible with JFIF, so the transition has been transparent to most users (O'Reilly & Associates, Inc., 1996 , http://www.ipahome.com /gff/textonly/summary/spiff.htm). Another addition to the JPEG standard is a new variant of the baseline JPEG algorithm, progressive JPEG. Also, a motion video compression format, commonly referred to as M-JPEG, has been developed and used by many companies. Unfortunately, M-JPEG is a non-standard variant of the JPEG algorithm, so many different implementations exist (Ohio State University, October 1997, http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-20.html). These additions and variations, however, do not fit within the scope of this paper, which focuses on the baseline lossy JPEG compression algorithm.
The JPEG image compression algorithm was developed by the Joint Photographic Expert Group in the late 80’s and early 90’s. In order to create a compressed image file, the original image is passed through a series of sub-algorithms and data structures. The entire process creates an output file with enough information to recover the now highly compressed image.
This paper will trace through the JPEG sub-algorithms and their associated data structures. Plain English explanations will be given on how the image data is structured, restructured, and finally written to file in a recoverable, SPIFF format.
There are four key steps (sub-algorithms) in the JPEG compression algorithm. The first step is to extract an 8x8 pixel block from the picture. The second step is to calculate the discrete cosine transform for each element in the block. Third, a quantizer rounds off the discrete cosine transform (DCT) coefficients according to the specified image quality (this phase is where most of the original image information is lost, thus it is dubbed the lossy phase of the JPEG algorithm). Fourth, t he coefficients are compressed using an encoding scheme such as Huffman coding or arithmetic coding. The final compressed code is then written to the output file.
Section 1 of this paper will discuss how the extracted data from the original image is structured and optionally manipulated. This discussion will encompass the first step of the JPEG compression process. Section 2 will explain the complex mathematical formula applied to an 8x8 pixel block in order to calculate the block’s DCT coefficients. Section 3 will discuss how the DCT coefficients are quantized and how quantizing affects the overall image quality. Section 4 will explain how the 8x8 matrix of quantized DCT coefficients is structured for more efficient encoding. Section 4 will also discuss the different encoding schemes allowed under the JPEG standard will be discussed.
Section 1 - Initial Input
The first step of the JPEG compression process is actually quite straight forward. Source image samples are grouped into an 8x8 matrix (see Appendix A), or block. The initial image data is usually converted from normal RGB color space to a luminance/chrominance color space, such as YUV. YUV is a color space scheme that stores information about an image’s luminance (brightness) and chrominance (hue) (Hung, 1993). Since the human eye is much more sensitive to luminance than chrominance, you can afford to discard much more information about an image’s chrominance, especially the higher frequencies. By using a YUV color space scheme, it is much easier to identify chrominance and thus eliminate unnecessary image data that cannot be seen by the human eye. It IS NOT necessary to change the image’s color space, but overall image compression will be less if you use the RGB color scheme since you will need to encode all of the components of the luminance quality. It is also worth noting that there is no benefit (and therefore not necessary) to use YUV color space on a grayscale image (Leemans, n.d.). Another optional manipulation to the image data is to downsample the chrominance components by averaging groups of pixels together. Since chrominance is less visible to the naked eye, downsampling it has very little visual effect on the image. Therefore, downsampling is a good way to obtain further image compression without sacrificing overal image quality. (O'Reilly & Associates, Inc., 1996, http://www.ipahome.com/gff/textonly/book/ch09_06.htm#JPCO). Once the image data in the 8x8 matrix has been satisfactorily manipulated, the matrix is inputted into the Discrete Cosine Transform mathematical algorithm.
Section 2 - (Forward) Discrete Cosine Transform (DCT)
Now that an 8x8 matrix has been extracted from the original image and is in the desired color scheme, the Discrete Cosine Transform (DCT) coefficients for each element in the matrix can be computed. The mathematical function for a two d imensional DCT is:
For decoding purposes, there is an Inverse Discrete Cosine Transform function, which is defined as follows:
It is not necessary to completely comprehend how these formulas work in order to understand how the JPEG compression algorithm works. The DCT encoding and decoding equations are simply provided for information and to demonstrate the complexity of the DCT functions.
Each element in the 8x8 matrix is inputted into the DCT algorithm, and translated into one "…of the 64 unique two dimensional ‘spatial frequencies’ which comprise the input image’s ‘spectrum’ (Wallace, 1991)." The ultimate goal of the DCT is to represent the image data in a different domain using the cosine function. The image data is transformed into numerous curves of different sizes. When these curves are put back together, through inverse Discrete Cosine Transform, the original image (or an extremely close approximation to it) is restored. After DCT, is the 8x8 matrix contains 64 DCT coefficients in which the first coefficient, commonly referred to as the DC coefficient, is the average of the other 63 values in the matrix. The other values, commonly referred to as AC coefficients, are simply DCT coefficients with no particular order (Wallace, 1991).
Section 3 - Quantization
Up to this point in the JPEG compression process, little actual image compression has occurred. The 8x8 pixel block that has simply been converted into an 8x8 matrix of DCT coefficients. Now it is time to prepare the matrix for further compression by quantizing each element in the matrix. The JPEG standard defines two tables of quantization constants, one for luminance and one for chrominance. These constants are calculated based on the JPEG image quality, which is usually selected by the user. The number used to calculate the quantization constants is stored in the JPEG image file’s header, making decoding of the coefficients possible. Once the tables have been constructed, the constants from the two tables are used to quantize the DCT coefficients. Each DCT coefficient is divided by its corresponding constant in the quantization table and rounded off to the nearest integer. The result of quantizing the DCT coefficients is that smaller, unimportant coefficients will disappear and larger coefficients will lose unnecessary precision. Quantizing produces a list of streamlined DCT coefficients that can now be very efficiently compressed using either a Huffman or arithmetic encoding scheme (Zaiane, June 1996).
As you can see, quantizing is an essential step in the JPEG compression process. Not only is the image partially downsized, but some of the original image quality is lost during this step. This is why JPEG image compression is a lossy comp ression algorithm. Although the actual image data lost is usually not visible to the human eye at normal magnification, (image degradation can be seen by the naked eye if an image is encoded to a low quality JPEG or if the image is magnified to many time s its normal size) the original image quality has now been permanently lost.
Section 4 - Encoding
The final step in the JPEG compression algorithm (prior to writing the image information to file) is to encode the data using a run length encoding scheme. Before the matrix is encoded, it is arranged in a zigzag order. Also, the elements representing low frequencies are moved to the beginning of the matrix and elements representing high frequencies are put towards the end of the matrix. By placing the higher frequencies (which are more likely to be zeros) at the end of the matrix, longer sequences of zeros are more likely to occur; thus, better overall compression can be achieved (Wallace, 1991).
Either Huffman (see Appendix B) or arithmetic encoding schemes are allowed (by the JPEG standard) for final image compression. Although using arithmetic encoding often results in a smaller file size, it is not usually used because IBM, AT&T, and Mitsubishi all own patents on the variant of arithmetic coding that is defined in the JPEG standard. In addition, some feel that arithmetic encoding is much more difficult to use for certain implementations of the JPEG algorithm, like high speed hardware implementations. Therefore, Huffman encoding is the predominant compression scheme used to further compress image blocks before they are written to file (Ohio State University, October 1997, http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-18.html)
Conclusion
Image compression is an extremely important part of modern computing. By having the ability to compress images to a fraction of their original size, valuable (and expensive) disk space can be saved. In addition, transportation of image s from one computer to another becomes easier and less time consuming (which is why image compression has played such an important role in the development of the Internet). The JPEG image compression algorithm provides a very effective way to compress im ages with minimal loss in quality. Although the actual implementation of the JPEG algorithm is more difficult than other image formats, (such as GIF) and the actual compression of images is expensive computationally, the high compression ratios that can be routinely attained using the JPEG algorithm easily compensate for the amount of time spent implementing the algorithm and compressing an image.
Appendix A
Huffman Tree
The Huffman encoding scheme was developed by David A. Huffman in 1952. The algorithm outlined by Huffman achieves data compression by encoding data based on its frequency. The data structure used to actually encode the data is a weighte d binary tree, or Huffman tree.
Properties
A Huffman tree has several unique properties:
1. A Huffman tree must be a binary tree.
2. A Huffman tree is weighted; elements appearing often in the data stream are towards the top of the tree while rarer occurring elements sink to the bottom of the tree.
3. Each left branch of a Huffman tree is assigned a value of zero, and each right branch of a tree is assigned a value of 1 (or vice versa).
Basic Algorithm
In order to construct a Huffman tree, two passes must be made through the data. On the first pass, a list of unique data elements and their frequencies is constructed. This is sorted in ascending order, thereby putting the most frequen tly occurring data elements at the end of the list. Next, the actual Huffman tree is constructed. The tree is built by taking the two elements with the lowest frequencies and making them the leaves of a tree. The parent of the two leaves is the sum of the leaf’s frequencies. The tree is then inserted into the list (the parent node’s value is used to determine where to insert the tree), and the two leaves used to make the tree are removed from the list. This process continues until there is only one e lement left in the list, which is the parent node of the final Huffman tree.
Before the Huffman tree can be used to encode the data, a way to uniquely identify each value in the tree must be established. This is done by assigning each left branch in the tree a value of zero and each right branch in the tree a value of one. Now it is possible to uniquely identify each element in the tree by using the 0’s and 1’s assigned to the tree’s branches. A table containing the unique code for each leaf in the Huffman tree is generated by traversing the tree and outputting a zero ea ch time a left branch is taken or outputting a one (1) each time a right branch is taken. Normally the Huffman tree is traversed backwards, starting at the desired leaf. This is because the resulting code’s first bit MUST start from the top of the tree.
The only step that remains is to pass through the original data again and output to file each data element’s associated Huffman code. Since the Huffman code representation of most (if not all) data elements is smaller than the data element itself, data compression is achieved. Since the output file contains Huffman codes, the original encoding information (like the Huffman tree or the data table generated from the Huffman tree) must also be stored in the output file in order for decompression to be possible.
Operations
There are many operations needed by a Huffman tree. The following is a list of the general operations used to create, manipulate, and utilize a Huffman tree.
There are many other functions that may be included in a full implementation of a Huffman compression program. The functions listed above are most of the main functions that will be needed in virtually any implementation of a Huffman tree data str ucture.
Uses
The Huffman encoding scheme and associated data structure is commonly used in JPEG image compression and MPEG video compression.
Example
Let’s look at an example of how the Huffman tree data structure is constructed and used to compress data. Suppose we have the following list of characters and their respective frequencies of occurrence:
|
Character |
Frequency |
|
b |
7 |
|
d |
13 |
|
a |
17 |
|
c |
22 |
|
g |
45 |
|
e |
77 |
|
f |
90 |
Notice that the above table is sorted by frequency in ascending order. This is how the list MUST be sorted in order to utilize the Huffman algorithm. Now, let’s re-write the table in a linear list, being careful to maintain the list’s ascending order :
Step 1:

Now, we construct a tree from the two values with the lowest frequencies. Each value becomes a leaf and the parent of the two leaves is the sum of the leaf’s frequencies. The list is now re-constructed, again making sure that it is sorting by frequen cy:
Step 2:
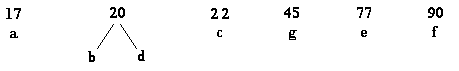
Continue constructing new trees from the two lowest frequencies in the list. The remaining steps to building a Huffman tree in this example are given below:
Step 3:

Step 4:
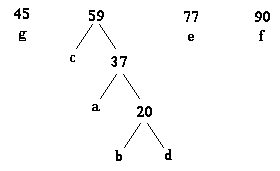
Step 5:

Step 6:
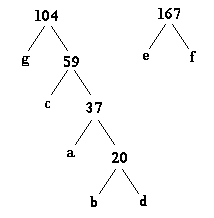
Step 7:
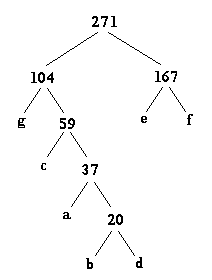
There is one final modification to the Huffman tree that must be made before the newly constructed tree can be used to encode data. In order to produce unique codes for each character, a zero is assigned to each left branch in the tree and a one (1) i s assigned to each right branch in the tree. The final Huffman tree looks like this:

The character codes for the above tree are:

Now you can use the derived Huffman codes for your original values. Notice that the Huffman codes for these characters are all shorter than the standard 8-bit ASCII representation of a character. Thus, when these values are written to file, data comp ression will occur.
Comparison (to other data structures)
To my surprise, there are relatively few other data structures used in image compression (which, as you will recall, is the focus of this paper). A matrix is often used to represent an image block. However, a matrix does not sha re many common properties with a Huffman tree. Most other image compression algorithms do not have a defined data structure; therefore, it is hard to compare a Huffman tree to other image compression data structures.
The Huffman encoding algorithm, when compared to other image compression algorithms, is quite good. Run length encoding is probably easier to implement, but its compression ratios are only good for certain types of files (like images) where long s equences of repeated data are present. Even when working with a favorable format (an image), the compression ratios achieved by run length encoding are very limited.
Entropy coding is probably harder than Huffman to implement. A nice feature of entropy encoding is that the dictionary used to encode the data does not need to be stored in the output file, thereby saving space. Unfortunately, this type of compre ssion is limited by the size of its data dictionary. It becomes impractical to use entropy encoding if the dictionary’s size is rather large (the largest practical size is approximately 256). A well known use of entropy encoding is the Lempel/Ziv/Welch algorithm, which is the basis of the Graphics Interchange Format (GIF) image compression algorithm.
Area coding is an improved form of run length coding. It is primarily used to compress images, since it’s algorithm (group the image into rectangular regions containing similar or identical image characteristics) naturally represents the two dimen sions of an image. Although area coding can achieve high compression ratios, it is non-linear and therefore cannot be implemented at a hardware level. For that reason, area coding is not highly competitive with the previously discussed image compression algorithms.
Arithmetic encoding is also a fairly good compression algorithm, but as mentioned earlier many companies own patents on variants of it. Therefore a license is required in order to use the algorithm, thereby increasing the overall cost of producing any product using arithmetic encoding (Open Information Interchange, July 1997).
Drawbacks
Although the Huffman tree data structure is usually quite good at achieving compression, there are drawbacks to using the Huffman encoding scheme. One drawback is that the actual output file is larger than it needs to be. This is becau se information about the compressed data’s frequencies must also be stored in order to make data decompression possible. Another drawback is that the data must be traversed twice; once to obtain the frequencies of unique data elements and a second pass w hich actually converts the data to its associated code and writes the code to the output file. Finally, overall compression using the Huffman encoding scheme is not always very high, especially when the data has a very uniform distribution.
Conclusion
Data compression is an extremely important part of modern and future computing. Although a Huffman tree is an older data structure, it is still a very reliable way to structure a wide variety of data in order to compress it. A Huffman t ree is easier to implement than most other compression algorithms, yet good compression ratios are routinely achieved. Ease of implementation and solid compression ratios are two of the reasons that the Huffman tree is an extremely popular data structure in modern data compression.
Appendix B
Matrix
A matrix is one of the most fundamental data structures in computer science. It may be helpful to think of a matrix as an n by m grid of values, where n is the length of the matrix and m is the height of the matrix. This grid is commonly stored in either row or column format, although other formats (like zigzag) are occasionally utilized.
Properties
Properties of a matrix often depend on its intended use (and implementation for that use). One of the most common (and easiest) ways to represent a matrix is by using a multidimensional array. There are, however, no straightforward pro perties of a multidimensional array representation of a matrix that need to be mentioned in this section. One characteristic of a matrix that is worth noting is that the worst case time performance for complete traversal of a matrix represented by a mult idimensional array is O(n2), which is rather expensive computationally.
Operations
Operations on the matrix data structure depend almost exclusively on what the matrix is representing and what the intended use of the matrix is.
Uses
The matrix data structure has a cacophony of practical uses in the world of computing. Therefore it would be useless to try and list all of them here. Some common implementations of the matrix data structure include the following: mat hematical matrix multiplication, two dimensional image blocks, grid representation, and many other areas.
Example
Here is an example of one use of a matrix. Pictured below is an 8x8 matrix representing valid checker squares on a checkerboard. Each valid square is numbered from 1 to 32, and each invalid checker square is given a value of zero. This demonstrates how a matrix can be used to represent a real world object.
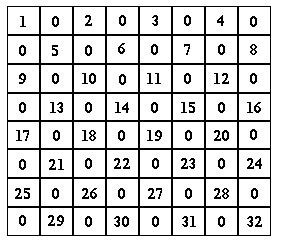
Comparison (to other data structures)
Not discussed within the context of this paper.
Conclusion
The matrix data structure, although costly to traverse and not extremely memory efficient, compares rather favorably to other data structures. A matrix is easy to implement, and its versatility is astounding. There are few other data s tructures that offer the ability to represent so many different kinds of real-world objects, mathematical functions, and other data formats so easily. Versatility and ease of implementation make the matrix a very common, powerful data structure.
References
American Psychological Association. (1994) How to Cite Information From the Internet and the World Wide Web. Retrieved November 14, 1997 from the World Wide Web: http://www.apa.org/journals/webref.html
Data Analysis BriefBook. Discrete Cosine Transform. Retrieved from the World Wide Web: http://www.cern.ch/Physics/DataAnalysis/BriefBook/
DiVecchio, Mark. (n.d.) Data Compression Techniques Using SQ and USQ. Retrieved November 30, 1997 from the World Wide Web: http://www.polarnet.com/Files/Mirrors/Simtel2/00_start/squeeze.txt
Filippini, Luigi. (1996) A Quick Tutorial on Generating a Huffman Tree. Retrieved November 19, 1997 from the World Wide Web: http://www.crs4.it/~luigi/MPEG/huffman_tutorial.html
Fokker, Jeroen. (1995) Functional Specification of the JPEG Algorithm. Retrieved November 30, 1997 from the World Wide Web: http://www.cs.ruu.nl/~jeroen/article/jpeg/index.html
Hung, Andy C. (1993) ISO IS-10918 - Understanding JPEG Image Compression. Retrieved November 30, 1997 from the World Wide Web: http://icib.igd.fhg.de/icib/it/iso/is_10918-1/pvrg-descript/chapter2.5.html
King, Andrew B. (May 1997) Optimizing Web Graphics: Compression - webreference.com. Retrieved November 30, 1997 from the World Wide Web: http://www.webreference.com/dev/graphics/compress.htm
Leemans, Paul. (n.d.) How Does JPEG Compress?. Retrieved November 30, 1997 from the World Wide Web: http://cs.wpi.edu/~nemleem/jpeg5.html
O'Reilly & Associates, Inc. (1996) GFF Format Summary: SPIFF. Retrieved November 22, 1997 from the World Wide Web: http://www.ipahome.com/gff/textonly/summary/spiff.htm
O'Reilly & Associates, Inc. (1996) JPEG Compression. Retrieved November 22, 1997 from the World Wide Web: http://www.ipahome.com/gff/textonly/book/ch09_06.htm#JPCO
Ohio State University. (October 1997) JPEG image compression FAQ, part 1/2 - [8] What is color quantization?. Retrieved November 14, 1997 from the World Wide Web: http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-8.html
Ohio State University. (October 1997) JPEG image compression FAQ, part 1/2 - [11] What is progressive JPEG?. Retrieved November 14, 1997 from the World Wide Web: http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-11.html
Ohio State University. (October 1997) JPEG Image Compression FAQ, part 1/2 - [14] Why all the argument about file formats?. Retrieved November 14, 1997 from the World Wide Web: http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-14.html
Ohio State University. (October 1997) JPEG Image Compression FAQ, part 1/2 - [18] What about arithmetic coding?. Retrieved November 14, 1997 from the World Wide Web: http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-18.html
Ohio State University. (October 1997) JPEG image compression FAQ, part 1/2 - [20] Isn't there an M-JPEG standard for motion pictures?. Retrieved November 14, 1997 from the World Wide Web: http://www.cis.ohio-state.edu/hypertext/faq/usenet/jpeg-faq/part1/faq-doc-20.html
Open Information Interchange (July 1997) OII Guide to Image Compression. Retrieved November 28, 1997 from the World Wide Web: http://www2.echo.lu/search97cgi/s97_cgi?Action=View&VdkVgwKey=%2Fextra%2F www%2FIM-EUROPE%2Fpub%2Foii%2Fen%2Fcompress.html&QueryZip=huffman&Collection=echoall
Open Information Interchange (November 1997) OII - Raster Graphic Interchange Standards Retrieved November 30, 1997 from the World Wide Web: http://www2.echo.lu/oii/en/raster.html#JPEG
Scott, John. (n.d.) Huffman Coding. Retrieved November 28, 1997 from the World Wide Web: http://www-students.doc.ic.ac.uk/~jcs2/huffman/
Su, Min-Hua. (n.d.) Senior Project: Introduction. Retrieved November 30, 1997 from the World Wide Web: http://www.isc.rit.edu/~mhs1938/SENIOR_PROJECT/index.html
theimage.com. (1997) JPEG File info. Retrieved November 29, 1997 from the World Wide Web: http://theimage.com/web/graphic/jpgvsjpg/gif2A.html
Wallace, Gregory K. (December 1991) The JPEG Still Picture Compression Standard. Retrieved November 30, 1997 from the World Wide Web: http://icib.igd.fhg.de/icib/it/iso/is_10918-1/sec.html
Weissenbacher, Bas. (n.d.) Bas Weissenbacher's Data Compression Page. Retrieved November 30, 1997 from the World Wide Web: http://www.kers.nl/mensen/bas/compress.htm#huffman
Wide Area Communications. (1996) GIFs and JPEGs. Retrieved November 30, 1997 from the World Wide Web: http://www.widearea.co.uk/designer/compress.html
Zaiane, Osmar R. (June 1996) 4.2. Video Compression. Retrieved November 29, 1997 from the World Wide Web: http://fas.sfu.ca/cs/undergrad/CourseMaterials/CMPT479/material/notes/Chap4/Chap4.2/Chap4.2.html#JPEG
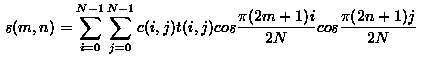 (
(