2011-09-11
Jim
Looking at SLP (Speech and Language Processing)
Chap 1
is an overview of the history of the field.
Useful background information, but mostly just
definitions of terms and a statement of what
was doable when.
Chap 2
defines regular expressions, first informally using Perl's syntax,
then more formally with DFAs and NFAs (text calls DFSA and NFSA)
(deterministic and non-deterministic
finite automata; text adds word 'state' and calls 'em DFSA and NFSA)
and definitions of
regular languages. Our "Formal Languages"
course that Matt and I do covers these topics
in more detail than the text here does.
The exposition in the text is OK, but
feels like a a funny mix of formal vs practical.
On the formal side they don't do enough of the
proofs to really feel like you could do the math;
on the practical side, they don't do enough
of the perl regex stuff (or the DFAs) to really feel like
you could program it. Nor do they mention
the difference between the formal definition
of "regular language" and what a Perl regex
can identify. (Perl and other regex engines
have more power in them then formal regular languages,
with conditional and other look-ahead forms.)
I guess you could learn either of these from
other sources, but ...
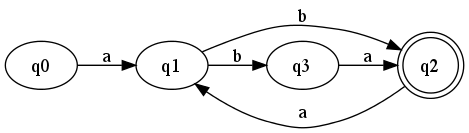
Problem 2.8 would be a reasonable place to start to
to test your understanding, namely : Write a regular
expression for the language accepted by the following NFSA.
# graphviz source for the NFSA diagram for problem 2.8
--- nfsa.dot ---
digraph nsfa {
rankdir=LR # left to right
q2 [shape=doublecircle]
q0 -> q1 [label="a"]
q1 -> q2 [label="b"]
q2 -> q1 [label="a"]
q1 -> q3 [label="b"]
q3 -> q2 [label="a"]
}
--- command line ---
$ dot -Tpng nfsa.dot > nfsa.png
Elias
Exercise 2.8
(ab)* + (aba)* + (ab)*
=> The language accepts strings with any number of the iterations of the substring "ab" and any number of iterations of the substring "aba", in any order.
Examples:
- Accepted strings:
- "ab"
- "abab"
- "ababa"
- "aba"
- "abaab"
- "abaaba"
- Unaccepted strings:

![[paper clip]](/courses/source/wiki_images/paper_clip_tilt.png)