2012-04-04
Aside
Work for Plan Project: I wrote a short program that does a quick string comparison. Similar to Hamming Distance, in that it looks at how many differences there are in the string. Then it divides this number by max(len(str1),len(str2)).
Text Classification
General Questions:
- What type of document is this?
- Eg: Spam/Ham; Author is male/female (assuming we have some differences for classification);
- What is this document about?
- Eg: Categorization (CS/AI/NLP/MT/...)
- What is the sentiment of this document?
- Good/bad (review); happy/sad; ...
How to do it?
- Train, test sets
- For naïve systems, split documents 70/30 test/train
- "Train" (teach the system) what it should look for in each case.
i.e., what means "happy"/"sad" or what determines categorization?
Naïve Bayes Categorization:
- AKA "Bag of words." Only count the words. Nothing else. Probabilities come from how many times a word is classified in certain ways.
P(d|c).P(c)
P(c|d) = -----------
P(d)
c=class, d=document
(In the lecture, MAP in c_MAP = "Maximum A Posteriori Probability")
c_NB = argmax P(c_j) . Product P(x|c)
c in C x in X
- First: Extract Vocabulary from training corpus (will be used for calculations)
- Then: Prob(c_j) = number of docs_j/total number of documents
- Make mega doc. Then find P(w_k|c_j). number of occurrences/size of vocab. (Smoothed if necessary.)
Maximum Likelihood Estimates (MLE)
- Frequencies. (Out of all words in document, how many times does each word appear)
- Mega-document. Concat all similarly-classified documents together.
- No MLE for NB.
- Use Laplace (add-1) Smoothing instead
What do we do with unknown words?
- Add an unknown word to the vocabulary ("w_u"?)
P(w_u) = 1/|all counts|+|V+1|
Close relationship to lang. modeling.
- Each class is a unigram language model.
| correct not correct
------------|------------------------------------
selected | true pos false pos
not selected| false neg true neg
(true pos + true neg)
Accuracy = ---------------------
(tp+tn+fp+fn)
Useful measure? Usually. But not in cases where we have very few true positives.
- mentions of shoe brands in web pages <- example from lecture.
- mentions of "technical jargon" (for something) in web pages
- ...
Precision:
- Of the things you are selection, what % are correct things? (tp/tp+fp)
Recall:
- Of the things that are correct, what % did we find? (tp/tp+fn)
There is a trade-off. How important is precision? How important is recall?
NLP systems: there is almost always this trade-off.
F-measure: combination of precision and recall.(Weighted harmonic mean) - very conservative avg.
F = 1/(alpha(1/P)+(1-alpha)(1/R)) = (beta^2 +1)PR/(beta^2 . P)+R
F_1 = 2PR/(P+R)
Example: Given that a classification system has precision and recall of P=0.75, R=0.25:
Averaging: Micro and macro:
- Microaveraged score is dominated by more common class. (i.e. if there are more elements in one class, it raises the microaverage.)
- Macroaveraged score says more "true things" about the data. (tp/(tp+fn))
We need Train|Dev|Test sets. To avoid overfitting.
Easiest way to automated split:
Multiple splits for dev set. Compute pooled devset performance. Then still use testset.
Underflow prevention. Multiplying lots of fractions: floating pt. underflow.
Sentiment Analysis
Products/polls/anything really.
- As long as there is written information that can be classified as positive or negative.
Look at all words, not just adj. We can get information from nouns etc.
Boolean Multinomial Naïve Bayes:
- Delete duplicate words
- Bayes rule as usual
Only changes between no occurrence and an occurrence of a word affect the calculation.
Train
1 Computer Science Computer Jim CS --> Computer Science Jim C(Computer|CS) = 3
2 Natural Language Processing Computer CS --> Natural Language Processing Computer
3 Syntax Computer Language Programming CS --> Syntax Computer Language Programming
4 Syntax Semantics Grammar Syntax LIN --> Syntax Semantics Grammar C(Semantics|LIN) = 1
Test
5 Semantics Grammar Language Computer ? LIN
There are many sentiment lexicons. Inquirer, Linguistic Inquiry and Word Count (LIWC), MPQA Subjectivity Clues Lexicon, ...
SentiWordNet Pos,Neg,Obj
What about if we want to make our own lexicon?
Hatzivassiloglou and McKeown
- "and"/"but" similar/opposite polarity
- Clustering algorithm?
- This is generally accurate in finding positive/negative "polarity" words, but there will almost always be some error.
- Slide example: Positive: "disturbing," "strange;" Negative: "cautious," "pleasant," "outspoken."
Turney Algorithm
- Extract a Phrasal lexicon from reviews
- Learn polarity of each phrase
- Rate a review by the average polarity of its phrases
(from slides)
Extract two-word phrases with adjectives, with certain restrictions:
- e.g. Adj-N-?, Adv-Adj-!N, Adj-Adj-!N, N-Adj-!N, Adv-V-?
Intuition: Positive more often with "excellent", negative more often with "poor".
How to measure co-occurrence (how often they appear together)?
Mutual Information!
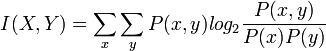
Pointwise Mutual Information (how much more do often words co-occur than if independent?):
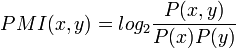
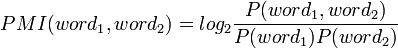
The "words" can also be phrases, and the calculation is done in the same way. The probability of the individual N-grams in the phrase isn't important... it's the phrase itself.
Turney was shown to be 74% accurate.
It learns "domain specific information" (aka. "Field of Knowledge" information).
Intuition:
- Start with "seed set of words" (basic "good" and "bad", +/- polarity words).
- Find other words that have similar polarity:
- "and" / "but" (see earlier)
- Nearby words in same document
- WordNet (repeating synonym/antonym chains)
Other sentiment tasks:
- What are we talking about: "field of knowledge", "domain", "subject" of review.
- Frequent word phrases
- Rules like "occurs right after sentiment word"
In-lecture problem: "Suppose we've found that "action scenes" is among the most frequent phrases in a set of movie reviews. Finding it in which of the following contexts would be most likely to lead us to select "action scenes" as a salient aspect/attribute/target for a review?"
- "...the action scenes"
- "...several action scenes"
- "...aerial action scenes"
- "...slow action scenes" <-- because it has a polarity word "slow" near it - logical assumption: "action scenes" is the target.
Sometimes, the "aspect" isn't actually mentioned, rather a defining aspect of the aspect is reviewed.
- Like for hotels and restaurants:
- Are we talking about food, décor, service, value, none-of-the-above?
How do we deal with that? Take a small corpus of restaurant reviews and label each sentence. It shouldn't take too long for "reasonably-sized" (depending on hardware) corpora.
Instead of finding the aspect from frequently-occurring phrases, we can determine it in advance (a priori). We then tell the classifier what we're looking for and find, for example, what the reviews about the food or décor at Bob's Restaurant were like.
Blair-Goldensohn algorithm:
Text Sentences Sentiment Aspect
Reviews -> extractor -> and -> Classifier -> S&P -> Extractor -> S&P -> Aggregator -> Final
Phrases
The baseline algo. assumes that classes (+/-) have equal frequencies. For toy examples, this is a valid assumption. But not always the case for the "real world."
We can use F-scores if the data is unbalanced.
Common solutions:
- Resampling in the training set
- Cost-sensitive learning
Assignment 3
Sentiment analysis: Classification of movie reviews into "positive" and "negative."
I've started looking at/playing around with it. It draws on many things we've seen in the AI class, as well as some of the "information" theory stuff from the Information Theory class. It's looking at the whole review. So, I'll probably do a count of "polarity words" and their co-occurrences (maybe 2-/3-grams) and look at probabilities that way.
Another thing the assignment mentions is "stop word filtering." Words like "the," "and," "it" ... I'm interested to see what effect it has on the system. I guess it makes it easier to get "good" data. We'll see.
Pseudocode that I should follow for the algorithm (from Information Retrieval by Manning, Raghavan, Schütze):
Spelling Correction Assignment (week 2)


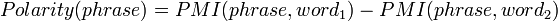
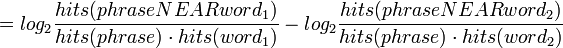
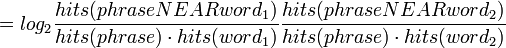
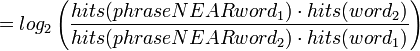

![[paper clip]](/courses/source/wiki_images/paper_clip_tilt.png)