Oct 28
I've made a few changes from last week. I'm getting most of my mathematical motivation for the method from more standard ratio estimation techniques, rather than the Probability Proportional to Proportion method from (Schreuder, 1968) that I had been using. All of the basic ideas are the same (the major change is that the scale factor is the average actual sampled populations over the average estimated sampled populations, rather than the average of the ratios) but I think this grounds things better mathematically, and gives estimation for the bias of the estimator, and a variance estimator that seems to be working better. The variance estimator looks at the actual population of a unit minus the population predicted by the method (scale*estimated population), rather than the difference between the population estimate and the population as estimated by one unit.
I also worked on some of the things we talked about last week. I got some census data for a few states and ran simulations. In general the correlations in populations between decades was pretty high so the results were pretty good.
I also made a few new ways to generate estimates. For one, you specify a range of scale factors and the population of each cluster is multiplied by a random number in that range. The other two have only one scale factor but also an error term. In one function the error term is a random variable from a Normal distribution centered at 0 with a standard deviation of sigma(entered by the user) times the mean of the actual cluster populations, and in the other the standard deviation for unit i is sigma times the actual population of unit i.
I've also been thinking about in what situations the method is useful. My sampling textbook has a section that talks about this, using the mean squared error. It talks about how the mean squared error of ratio estimation is less than the mean squared error of a simple random sample if the correlation between the estimated and actual populations is greater than the coefficient of variation of the estimated populations divided by two times the coefficient of variation of the actual populations. I've done some simulations that seem to confirm this, and am hoping to extend the analysis of usability to looking at the percent error of the point estimate and how often the actual population is in a confidence interval around the estimate.
I'm still working on how the derivation of a few things works. The variance estimator is derived using a first order Taylor series approximation, and there are a few things that I'm not clear about I was hoping we could discuss if there's time.
Jim
math in this wiki :
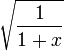
or x2
