assignments
due Thu Jan 26
getting started
- Make sure you can log into this site. If you aren't on my roster yet, email me at mahoney@marlboro.edu .
- Read the "Introduction" chapter in Problem Solving with Algorithms and Data Structures, which reviews python.
- Use the Fraction class as described in the text to find exactly \( \sum_{n=1}^{100}\frac{1}{n^2} \) . (Anything interesting about that number? Hint: multiply by six and take the square root.)
- As one more python coding practice, find the ratio of consecutive Fibonnaci numbers for large n.
- bonus: Make a plot of n vs Fib[n] , fit to a curve of the form \( y = b x^a \) , and discuss.
due Thu Feb 2
analysis and "big-O" notation
- Read the Analysis chapter of our textbook.
- To give you some practice making a plot (I suggest IPython as discussed, but you can use any tool you like, as long as you submit a plot as part of your homework) and to think about the O() notion :
- Suppose the number of steps for two algorithms are \( f(n) = 10 n + 0.1 n \log(n) \) and \( g(n) = 0.01 n^2 \).
- Plot these functions.
- What are their O() behaviors?
- Which algorithm is faster?
- A sorting algorithm takes 1 second to sort 1000 items. About how long do you think it will take to do 10,000 items if
- the algorithm is O(n**2)
- the algorithm is O(n log(n))
- Consider the problem of implementing is_substring(a,b) which is True if and only if a which has m characters is a substring of b which has n characters . For example, if a="is" and b="My name is Jim.", then the answer to is_substring(a,b) is True. On the other hand, is_substring("one", "alpha beta gamma"), then it returns False.
- If the only operation you can preform is comparing characters(i.e. a[i]==b[j]), invent an algorithm that implements this algorithm. Any algorithm will do - it does not have to be the most efficient.
- Describe what you think the O() behavior of your algorithm is, in terms of m and n.
- Implement and test your algorithm.
- Measure the time it takes your code to run on random strings of varying length, and create a plot that explicitly shows the runtime for some choices of n and m.
- Repeat the previous numerical experiment using Python's built-in operation "a in b" which also returns True or False. (This will run very fast for most strings - you can time it by putting in a large loop to do it many times, then dividing the time for the whole loop by the number of times through the loop. Or check out python's "timeit" library.)
- What do you think is the O() behavior of Python's "a in b" operation?
- Discuss what you think are sorts of strings a and b give the best, worst, and average behavior of your is_substring algorithm. What do you think the O() behaviors are for these cases?
due Thu Feb 9
linked lists
- Read the Data Structures chapter in the text, particularly the Stack, Queue, and LinkedList parts.
- Implement and test a doubly-linked list in python which can serve as both a stack and a queue. Your API should include at least methods for __str__, push, pop (i.e. the stack API), enqueue and dequeue (i.e. the queue API), reverse, nth (i.e. return the n'th element of the list), and a way to insert a new element into the list.
- Describe the expected O() behavior of each method. Measure at least one with a numerical experiment to verify that it does have the O() behavior you expect.
due Thu Feb 23
recursion
- Read the recursion chapter.
- Write a program to recursively draw the Sierpinski triangle. (Hint: the python turtle can do this, using its fillcolor, begin_fill, and end_fill methods, and noticing that "erasing" can be the same as "filling white".)
- Pascal's Triangle is a famous array of binomial coefficients. (Google it if you are unfamiliar). Each term can be determined recursively from two smaller ones. Write a program to print out n lines of these coefficients. (Coding exercise 13 in the text.)
- Read the descriptions of coding exercises 14 (knapsack problem) and 15 (string edit distance). For one of these two, implement an algorithm using memoization. (These can also be done with dynamic programming, but I'm not requiring that. Both of these are well studied, so if you don't see how to proceed without help, google to find a discussion. If so, quote your sources.) Discuss briefly the O() behavior of your approach, and the brute force O() behavior (i.e. without memoization).
due Thu Mar 2
searching
- Read the sequential, binary, and hashing parts of the Searching chapter in the text. (We're doing sorting next, so continue on into that if time allows.)
- Write and test functions that do sequential and binary search on an ordered list of random integers, and show that binary is much faster for big lists, at least waving your hands at seeing the O(n) vs O(log n) difference. (That means I want you to demonstrate what's going on but am not requiring lots of data with graphs and curve fitting and all that.) You can use the textbook code (if so quote your sources), but make sure you understand what's going on.
- Write and test a program that stores strings in a hash table. All the details are up to you, including the choice of a hash function and how to handle collisions. Do explain what's going on, and what the pros and cons are of your choices. Again, you can use code from the textbook - or parts of their code - but if so quote your sources and make sure you understand it.
- Coming soon : a midterm numerical sorting project, due right before spring break. (You can work on this over break if you so choose.) Details coming.
due Fri Mar 10
midterm sorting project
- Choose two sorting algorithms to implement, test, analyze, and compare. Any of the ones in the text or that we've discussed are fair game. If you want to do a different one, check with me.
- For each, your mission is to
- Explain how it works - enough to convince me you understand it. Also explain what its O() behavior should be on random lists, and why. Discuss when (if ever) this algorithm might be an appropriate choice.
- Implement it.
- Test it, i.e. show it does sort lists successfully.
- Measure with numerical experiments the run time or number of steps it takes when sorting lists of random numbers of (at least) length 1e1, 1e3, 1e5, 1e7. Show explicitly with a graph that it has the O() behavior you expect.
- Rules of the road:
- I suggest an jupyter notebook since I would like to see some plots ... but that's your choice, as long as all the pieces are turned in.
- Don't work with other students or a tutor on this - I want to see your work. You may use online sources, but if so, quote exactly what you took from where. Do not just copy and paste code that implements one of these algorithms in one fell swoop - that is not a good way to demonstrate your understanding.
- This will be graded and will be 1/3 of your term grade. Your mission is to convince me you understand what's going on. Code and write-up clarity (API, docstrings, following conventions for the language) matters. Clear and thorough for a simple algorithm is better than a partly-finished and partially-understood complicated one.
- The due date is Friday before the break, but you can turn this in after break ... as long as I have it *before* our first class meeting after the break.
- If you have questions about any of this, ask me.
due Tue Apr 4
trees
- Read chapter on trees.
- Also check out several wikipedia articles on these topics, which are more complete and in several places I think clearer.
- Also check out python's built-in heap functions.
- Using any binary tree representation (in python) that you like, build a tree that represents the following algebraic expression : 2 + 3 * 7 + 3 * 5 * (3 + 6 * (4 + 5)). Implement a post-traversal (if you like buzz-words) recursive function that returns the value of such a tree, or of any sub-tree. (You do not need to write a general parser for such expressions, which would create such a tree from a string. What I'm asking for is that you build that a tree for this expression, using something like the insert() operations in the text, and then write something which calculates the value with a recursive function.)
- Explain what a "min heap" is, and why the various (peek, push, pop) operations have (O(1), O(log n), O(log n)) costs. As explained in the wikipedia article, there are two common 'heapify' algorithms which convert an entire collection to a heap, one of which is O(n log(n)), and one of which is O(n), as described in the wikipedia article. Optional: explain what's going on there.
- Describe what an AVL tree is, and why it's (push, pop, search) operations have O(log n) behavior. I'm not asking you to write code here - just wave your hands and maybe draw some pictures and put into your own words why these things are interesting.
due Tue Apr 11
graph basics
- Read the graphs chapter in the text, at least through the depth-first and breadth-first searching.
- Here is a tree
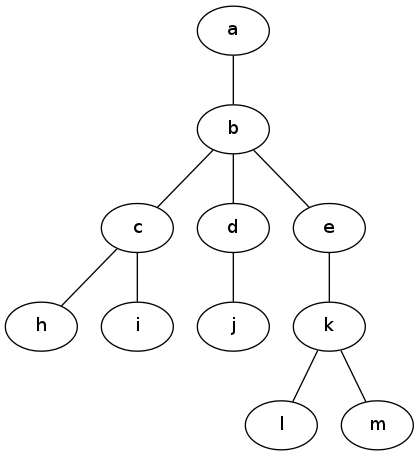
and a cyclic graph
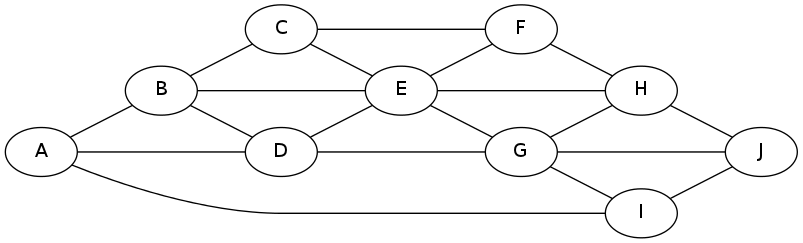
- Write down two computer representations for each of these, using (a) an adjacency matrix and (b) an adjacency list as defined in class and our text. (That's four representations altogether, using some computerish pseudo-code or Python or whatever.)
- Write down the order that the vertices will be visited for both of these, for both (a) a depth-first and (b) a breadth-first search (i.e. traversal), starting at "A" and "a". (You can do this by hand if you like or with code - just make sure you understand why the order is what you say it is.) Now do the same starting at "D" and "d".
- Define the "diameter" of a graph as a the longest of the shortest paths between vertices. Here's one algorithm that tries to find the diameter:
Pick any node, call it X. From X, do a depth-first search, and from
that find the maximum depth and a vertex furtherst down, call it A.
Now starting at A, do another depth first search, and find the
deepest node from A, call it B. Return the diameter (we hope) as
the depth from A to B.
Consider running this on a tree (an acyclic undirected connected graph)
and a cyclic graph, like the two illustrated above. Does the algorithm
work in either of these cases? Explain why you think so. What is it's
O() behavior? Extra credit: prove your claim in both cases.
- (Optional) Implement any of the tasks above.
due Tue Apr 18
more graphs
- Read about the "shortest paths" algorithms mentioned in this week's notes and come to class prepared to discuss them.
- Edit the depth-first-search code from our textbook , adding docstrings and tests (and fixing any of Jim's typos as needed). (Their github repo is https://github.com/bnmnetp/pythonds .) Run it on the cookbook example from the textbook and explain how it orders the vertices.
due Fri May 5
final project
- Choose one graph algorithm to discuss, implement, test, and analyze with a numerical experiment. Any of the ones we've discussed are fair game - I suggest Dijkstra's, Floyd's, Prim's, or Kruskal's. If you want to use something we haven't talked about, check with me first.
- Your mission is
- Explain how it works - enough to convince me you understand it.
- Explain what its expected O() behavior should be on a random graph, and why. (You will need to do a bit of reading and thinking about number of vertices |V| and number of edges |E|.)
- Implement it.
- Test it on a small graph, and show that it works the same way the algorithm does by hand.
- Measure its behavior with numerical experiments on randomly generated graphs of different sizes. You can use either the run time or number of steps it takes. (Don't include the time it takes to create the random graphs, only the time for the algorithm itself.) This is the main point of the project - don't skip it.
- Rules of the road - same as for the midterm. Please re-read.
- Extensions to the following Monday are available on request. (My grades are due soon after Monday. The following Wed noon is the school's hard deadline beyond which no work for this term can be accepted.)
term grade
- a place for overall feedback
