
This week, I've been trying to catch up to where I was before I got sick by working on the TweeTeX lexer. I decided that, in this simple case at least, to write it by hand without SLY. I've attached a copy of the code, though it's still not fully functional.
The problem I've been chipping away at is that python interprets any backslash \ followed by a character as an escape. So, if I open a file where the lines contain backslashes, the backslash and character at the beginning of the line isn't actually interpreted as the character \ + whatever other character follows it, but as an escape. So, all of my commands aren't matching properly.
I might have a solution in that I've replaced every instance of "\" with "\\", which adds an escaped backslash to each string that had an unescaped backslash, so that when the regular expression matching happens, the regex engine recognizes the backslash as a non escape character. I also had to do this with curly brackets. Still, I'm not sure I understand re groups very well...I'm trying to iterate over the line using the different tokens to match different components of each line of input but things are not going well.
Here's the input I'm using:
\title{My Story}
\author{Nick Creel}
\ifid{0CA8C7C5-F219-4B1B-A3A8-45710F389818}
\start{Starting Passage}
\passage{Starting Passage}
This is some text in the first passage
\link{Second Passage}{This link goes to the second passage}
\passage{Second Passage}
This is some text in the second passage.
and here's the output I'm receiving:
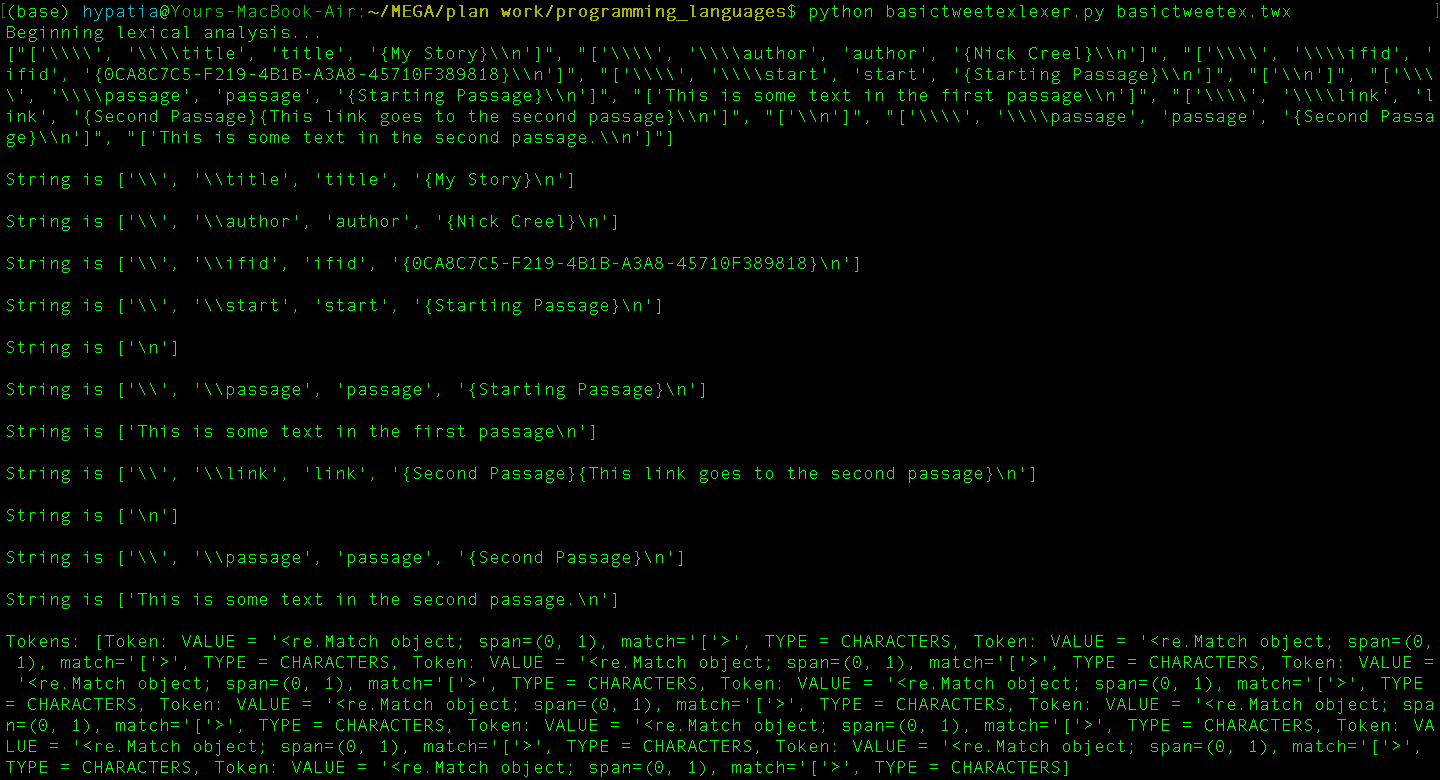 It seems that everything is being matched as a character (which makes sense? I guess I have not defined the CHARACTER token rigorously enough to exclude commands and curly braces...) and now there are too many backslashes (this started after I decided to split by multiple different tokens, so now I'm only splitting by COMMAND). There must be a better way to go about it, though.
It seems that everything is being matched as a character (which makes sense? I guess I have not defined the CHARACTER token rigorously enough to exclude commands and curly braces...) and now there are too many backslashes (this started after I decided to split by multiple different tokens, so now I'm only splitting by COMMAND). There must be a better way to go about it, though.
I think that you're confused about how python treats (a) characters in a file, (b) bytes in a file, and (c) string literals.
Python's strings changed quite a bit in version 3. I'm assuming your using Python 3.x since at this point 2.x is deprecated.
In python3, strings are sequences of characters (as opposed to sequences of bytes). There is a "bytes" type for sequences of bytes. See my attached unicode.py for examples.
Reading a file in string or byte format will not treat backslashes in any special way.
However, if you use print() to look at a string, python will use it's own string literal formatting rules to display it. See https://docs.python.org/2.0/ref/strings.html for the spec.
So give this file as sample.txt
This is some text with single \ and
double \\ backslashes in it.
then this python program will look at what's in it:
print("-- backslash character in a variable --")
backslash = "\\" # This is one character, not two.
print("This is a backslash : '{}'".format(backslash))
print("len(backslash) = ", backslash)
print()
text = open('sample.txt', 'r').read()
print("length of text is ", len(text))
for char in text:
pass
# to be continued ... print, check for equality with backslash
![[paper clip]](/cours/static/images/paper_clip_tilt.png)
| last modified | size | ||
| Screen_Shot_2019-10-15_at_1.25.20_PM.png | Sun Jun 21 2026 12:58 am | 80K | |
| basictweetex.twx | Sun Jun 21 2026 12:58 am | 300B | |
| basictweetexlexer.py | Sun Jun 21 2026 12:58 am | 4.1K | |
| find_slash.py | Sun Jun 21 2026 12:58 am | 552B | |
| jim_morphs_lexer.py | Sun Jun 21 2026 12:58 am | 2.6K | |
| tiny.txt | Sun Jun 21 2026 12:58 am | 23B | |
| unicode.py | Sun Jun 21 2026 12:58 am | 4.4K |

{kind=link}