
I've gotten a basic version of the lexer working after our discussion last week. I decided that trying to cram everything into one file was not practical, so I've separated all the code for the lexer into lexer.py, while actually executing the code on user input in tweetex.py
tweetex.py currently takes an argument via the command line when the program is executed, so to run it on a file you'd have to type "python3 tweetex.py foo.twx" (there's nothing checking the file extension as of yet. I just used one to distinguish visually between files)
I made a basic example of all the things that a tweeTeX file might contain and saved it to basictweetex.twx. When the lexer runs on this input, the following tokens are generated:
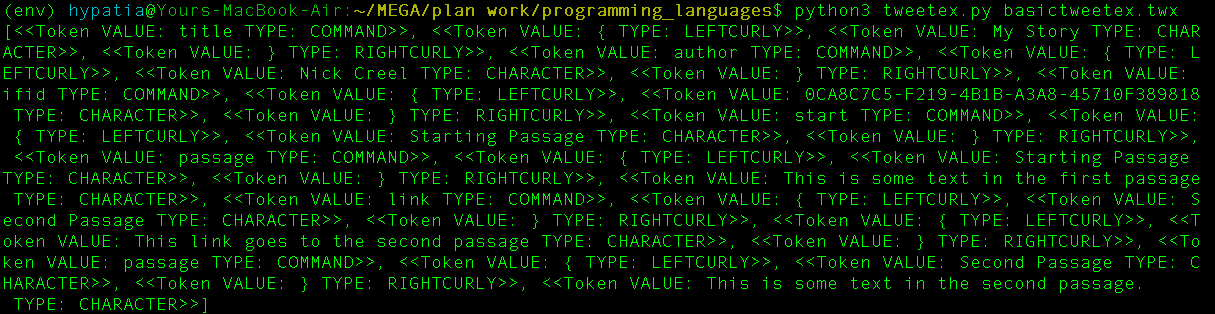
One note: for commands, rather than preserve the whole match (eg. "\hello"), I believe that only the name of the command ("hello") is important for the templating that needs to happen during parsing, so I've only saved the name when creating the token. Every other type of token stores the entire matched portion as the value, and will probably continue to do so.
It seems that my concerns about the lexer knowing when to stop are unfounded, as each command was recognized as a command rather than a character (it helps that the regex for character excludes slashes and curlies, of course). To make editing the string simpler, I captured each regular expression in a group so that I could find the length of the captured text and use that to modify the input for further parsing. see the next token method in lexer.py for the code:
def _next_token(self, source):
### get string
### match string to each regex
### if match, return string to lex function
### and append token to self.token
### else, break
string = source.lstrip()
if DEBUG:
print(f"string is {string}\n")
for token in self.token_types:
if DEBUG:
print(f"token is {token}")
match = re.match(token, string)
if match and len(match.groups())>1:
tokenobj = Token(match.group(2),self.token_types[token])
self.tokens.append(tokenobj)
if DEBUG:
print(string[len(match.group(1)):])
result = string[len(match.group(1)):]
return result
elif match and len(match.groups()) is 1:
tokenobj = Token(match.group(1), self.token_types[token])
self.tokens.append(tokenobj)
result = string[len(match.group(1)):]
return result
return False
another note: the thing currently called parser in tweetex.py is actually the parser for arguments entered via the command line, NOT a parser for tweetex. I've started working on the tweetex parser, but I really have nothing to show for that yet (minimally, I've made the file for all the parsing tools and started to think about how to write the recursive descent, but haven't actually done the coding.)
![[paper clip]](/cours/static/images/paper_clip_tilt.png)
| last modified | size | ||
| Screen_Shot_2019-10-28_at_2.35.53_PM.png | Sat Jun 20 2026 10:59 pm | 51K | |
| basictweetex.twx | Sat Jun 20 2026 10:59 pm | 300B | |
| lexer.py | Sat Jun 20 2026 10:59 pm | 2.2K | |
| tweetex.py | Sat Jun 20 2026 10:59 pm | 579B |

{kind=link}